HRTF 3D 音效简明算法
尊重原创,请勿转载!
作者:图林根の烤肠
最近毕设的UI设计已经大体上完工,在圣诞之际开始了音频的HRTF合成,由于这方面的相关资料不是非常全面,导师在过完一年一度的旅游假期后外加生病一星期(俺就就当做是真生病了)反而又到了圣诞长假,年前连半个个人影也找不到。同学Oli说过一句挺搞笑的话,科学家们经常把本来很普通的事情故意说得晦涩难懂,以证明自己非常牛叉。虽然导师给指点了一下,然而在看了很多资料后我仍是一头雾水,仍然没搞懂如何合成具体的 3D 音效,然而在读完 Mr. Li 论文中的代码后对 HRTF 的音频合成有了大致的了解,特此总结下相关知识,以减轻学弟学妹们为找不到资料发愁而带来的痛苦。
PS:本文特此感谢下 Mr.Li 的鼎力技术支持,至于说 Mr. Li 是谁? 我也不知道,那可是法兰火车站红灯区附近的名人~(偷笑)
这里给学校免费做个广告,欢迎各位同学来德国就读 伊尔梅瑙工业大学 的 媒体技术 专业,虽然这个学校总体不算出名,但是媒体技术这个专业在德国始终是前三名。 因为这边都是学分制,课程都是自选,如果不具有德语水平,除了个别课程没法用德语完成,英语也是没问题的~~~这个城市位于德国中部图林根州,风景秀礼,城市虽然很小,但是十分适合学习研究。如果你对音频领域感兴趣,这个方向的 IEEE Fellow, Mp3 之父 Brandenburg 教授,正是当年带领团队开发出举世著名mp3 格式的团队,紧邻学校还坐落着德国 弗劳恩霍夫应用研究促进协会 的数字多媒体研究院,正是全德国研究媒体技术的前沿专业机构。
闲话不扯了,正文开始。
HRTF 介绍
如果看到此文,表明您已经对HRTF(head-related transfer function)有一定的了解,随着这几年 VR 技术的不断发展,3D 音频的应用范围也得到了进一步的扩展,包括最近苹果 Air Pod 使用的虚拟空间音频,也是使用了类似的技术。通俗来讲,HRTF 数据库对应的频域范围的信号,与之对应的则为HRIR(head-related impulse response), 这里主要说明的是时域范围,通过 HRIR 与音频信号进行卷积来实现 3D 音效。当然,实现 3D 音效的数据库不止 HRIR,据导师说明,音效模拟的效果依次为: BRIR > HRIR > Stereo ,这里的BRIR的是binaural room impulse response), 相对HRIR 来说 BRIR 具有更多的空间信息(资料待考证) 。目前互联网上容易寻找的HRTF数据库是 CIPIC HRTF DATABASE(链接已失效),相关内容我会在下一篇文章中阐述。
合成方法
首先来说下实现3D模拟的算法,明白之后看代码就会容易许多。
1. 确定音频的播放位置:
我们知道,通过一段音频与对应的空间位置(azimuth和 elevation 角度)的 HRIR 数据进行卷积即可产生一段位于该点的空间音频。首先来做的是输入的音频在空间上需要分割为多少个点。这里如图所示(稍微将就下,个人手画水平实在不敢恭维),在头部的平面上(这里简化成 2D 平面,容易理解其算法),假如我们想要在 0°,60°,120°, 180°,300° 和 330° 这六个点合成信号。
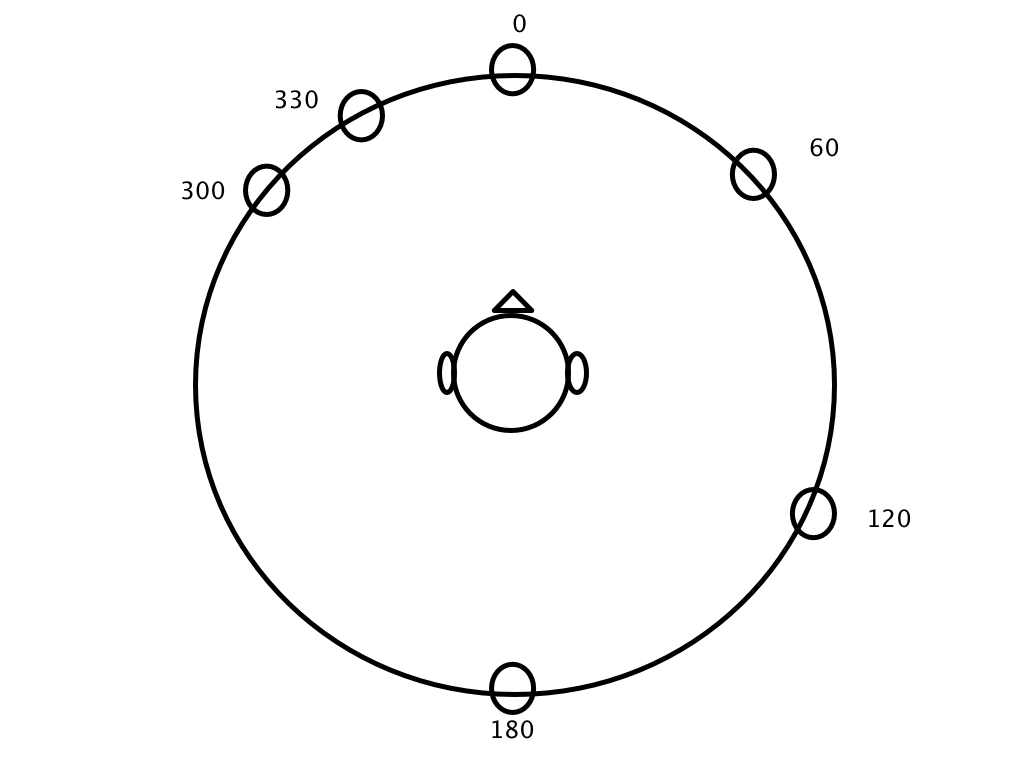
Azimuth 水平角,12点方向为0度
2. 分割音频为 N 份
每个点的音频时间可以均分或者不等分,均分的话容易计算,因为之前已经定义了6个点,所以这里把音频分为6等分。
|
|
假设音频长度为264600个采样点,采样率为44100的6秒片段,那么每段长度为 264600/6 = 44100 ,则每段音频长1秒。
3. 为每段信号进行卷积
接下来就需要对每一段的音频信号跟相对应空间位置的HRIR函数卷积。这里的算法为
|
|
5. 合并每一段代码后合成最后的声音
|
|
这里的加法在 Matlab 上面为数组的合并,并不是每一项的数学相加,而是: 输出 = [片段1 片段2 片段3 片段4 片段5 片段6 ]
4. 优化处理
细心的读者会发现上面的步骤是5而不是4,因为我们还需要在步骤5之前做接一些额外工作。
如果你按照1-5的步骤走下来后就会发现,如果只用四个步骤合成实际效果并不理想,因为我们总能在每一段的音频的衔接处听到断点,导致音频不连贯。我的做法是在每一段的开头和结尾加上淡入淡出的效果,即为每两段音频的连接处正常化处理。算法为:
4.1 利用窗函数来实现淡入淡出效果
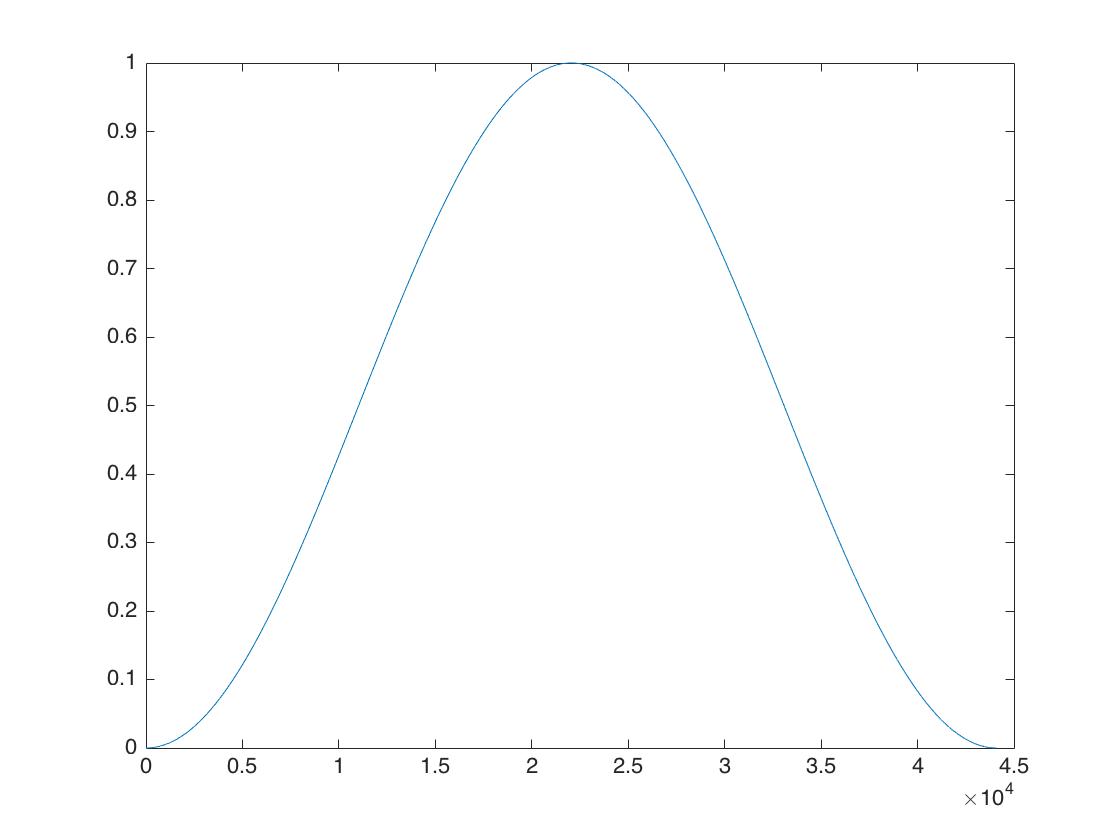
汉宁窗函数
这里用一个汉宁窗来实现淡入淡出,淡入取汉宁窗的前半段,淡出取后半段,这里的窗函数长度是自订的,窗函数长度 = 淡入长度 + 淡出长度。为了方便前后淡入淡出长度相等即可。及窗函数长度 = 2 * 淡入长度 = 2 * 淡出长度 = 淡入长度 + 淡出长度。如果想要淡入效果,即可使用汉宁窗的前半部乘以需要淡入的音频片段即可,就保证音频的平滑淡入过渡,淡出效果使用汉宁窗对后半部即可。
|
|
如果最后生成的音频仍有不连贯问题,可采用更改窗函数长度的方法反复试听,一般即可解决问题。
4.2 片段分解:
首先来看图片,因为图片理解起来比文字要具体不少:
我们需把每段的音频分为:淡入``中间音频``淡出 三部分:
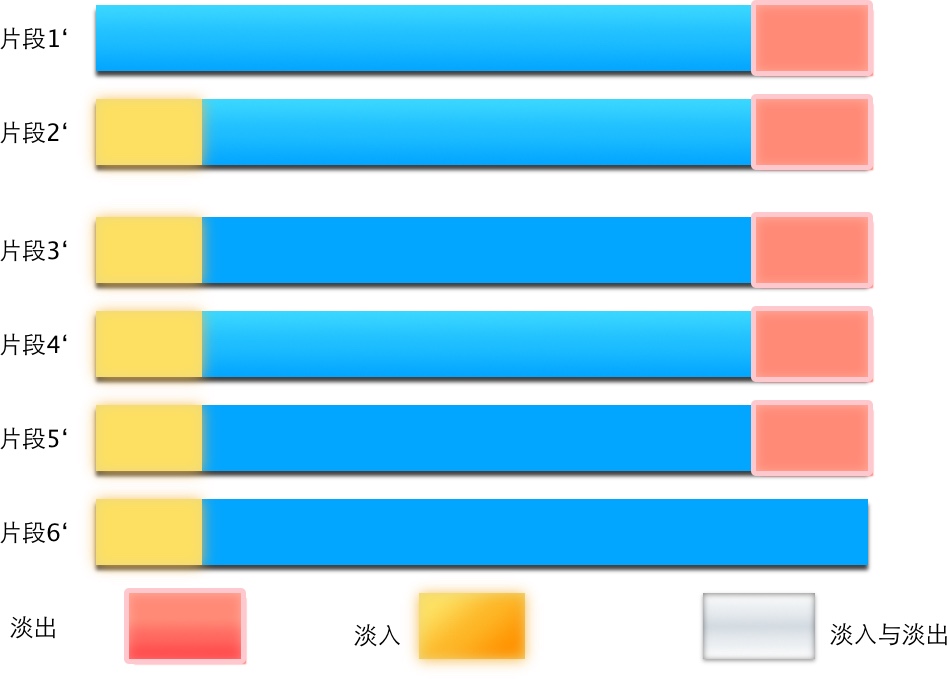
其中要注意的是:对于整个音频文件,添加淡入淡出效果的时候第一段音频不需要淡入音频,而最后一段音频不需要淡出,可以当做特例来进行处理。
4.3 合并淡入与淡出
把每一段音频进行淡入淡出处理后,我们就可以把每一段的音频合并起来了。这里拿片段2和片段3合成举例。因为片段2的音频结尾进行了淡出,为了保持连贯,需要把片段2的结尾与片段3的开头合并,即 红色部分和黄色部分重叠相加,才能实现连贯效果。
这里需要注意的一点是,不直接把片段1的淡出结尾直接与片段2淡入开头合并,因为这样会听到片段1点淡出效果,而片段2开头却听到了淡入效果。直接让片段1的淡出结尾与片段2淡入开头合并,可以形成更加自然的过渡效果。虽然这里我表达的有些绕口,那么看下面图片即可明白这里的意思:
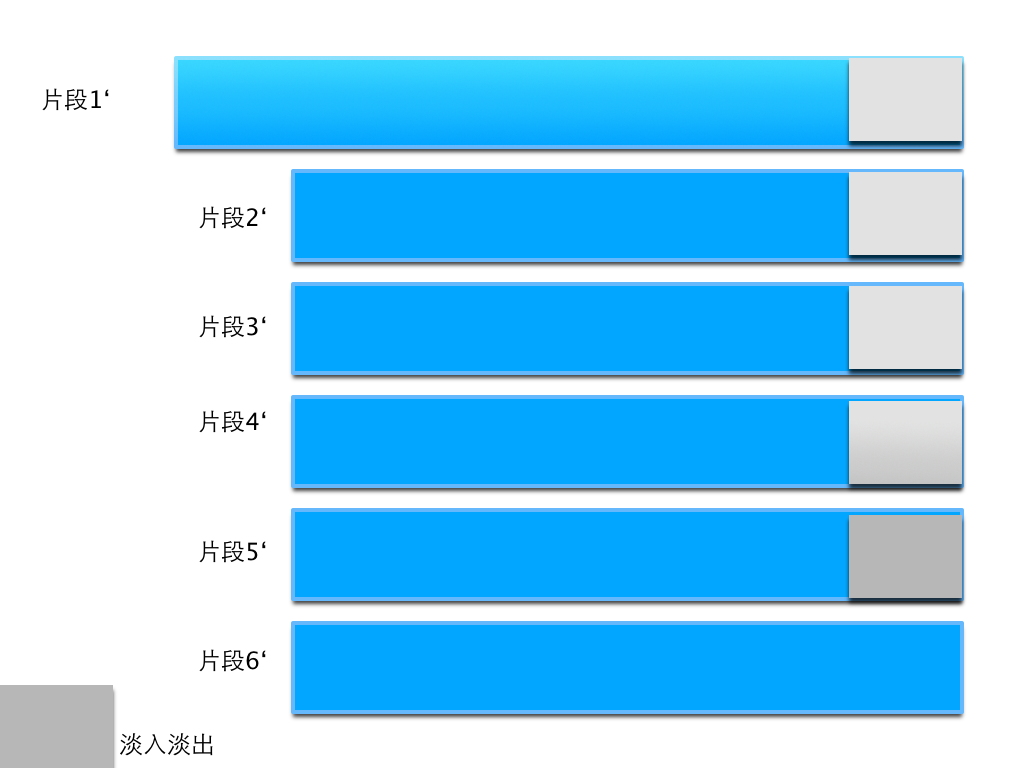
最后实现的效果是:在片段的末尾加上了淡入和淡出合并的效果,在片段的开头也加上了相应的效果。 上面的图片可以用接下的文字更加详细得解释:
|
|
这里抛开片段1,剩余的片段2到片段6长度均减少了窗函数长度的一半,少去的部分即为淡入(淡出)的长度,这里再举个实际的例子:
片段2原来长度 : 44100, 淡入淡出长度各为:256, 则可以推出:优化后的片段2’长度为:44100 - 256 = 43844,中间的部分长度为 44100 - 256 - 256 = 43588。还有一点需要注意的是,优化后的片段2’ = 片段2 [256+1: 43588] 即从原始片段2的第256个值开始到43588的值。
4.4 片段合并
再优化完每一片段后,最后一步就是把所有的片段合并即可,合并后的结果如图所示:

片段合成
总结
以上就是HRIR函数的具体算法,详细实现代码可以浏览我的 Github,当然我也会在我的 另一篇 文章中补充代码的说明。
最后的合并结果虽然少了5段淡入的音频 ,即256 * 5 = 1280个采样点,但是听起来更加平滑,其实如果整体的音频总是需要在一个点模拟,例如60度角度,那么完全没有必要进行片段合并,而是用整个音频文件卷积对应的空间位置的 HRIR 数据即可。这个片段淡入淡出效果的作用仅仅是为了让音频在空间位置转化的时候听起来不会出现明显的断层而使用。
当然了,如果您发现了更好的优化算法,也欢迎推荐给我,让我们一起讨论。